Critical Components
Introduction
A project has structural properties independent of context:
-
tasks may be related by their mutual dependence on a shared resource
-
tasks may be related by structural similarities in their relationships, both internal and external
-
tasks may be related because they interface directly or indirectly with each other
These relationships can be measured with a variety of metrics, but these metrics cannot be employed directly; they have to be further processed to yield qualitative measures, which themselves are subtle and open to interpretation.
Fortunately, it is relatively easy to identify problematic structural relationships without metrics. We call these relationships critical components.
Coupling
Computer science offers us a good conceptual platform for describing a critical component.
Data used by more than one program effectively couples the programs together. This would not be much of a problem if the data were simple and meant much the same thing to all the programs that employed it, but in practice data tends to become sufficiently complex that they bear their own context – a rather fancy way of saying that data should carry enough extra information with it to identify itself . For example, data from a radar system would consist not only of range and bearing values but the time the measure was made and some indicator that it is a time & position measurement. In large distributed systems the data tends to become ever more complex as it is collated with other data on its path from being created to the various command and control centers that employ it; it acquires information about siting, prevailing weather conditions, ambient noise, transmitter power, duty cycle, pulse-shape, etc.
In essence, the state and nature of a datum becomes more complex as it is forced to serve progressively more ends.
Inheritance
Object Orientation is one of the computer scientist's many counters to the ever-increasing complexity of coupling. Because a software object inherits the data and methods of its base-objects it encourages system engineers to design objects rationally and to keep them intact. No matter how complex a data object becomes the simple building blocks can yet be found inside it. If our radar system were replaced with another system that measured time & position + velocity, we could simply change our base-object to incorporate the new velocity information, and the system would still function happily while it learned to use the new information (which would be immediately available throughout the system). We could not easily reverse this. Reducing data complexity is extremely difficult; if a low-level object ceases supporting a method then all the objects that inherit from that object must supply their own alternatives.
Because of inheritance it is a relatively easy operation to track data back to source. No matter how long the chain may be, each link in the chain points us at the previous one. This is a property of an object-oriented system, and while it is possible to build an object oriented system that breaks this rule it is much easier to build one that doesn't.
Complexity
There are relatively few elements that conform with the synthetic purity of the abstract design process. As we add elements to our system and interface them with each other we are building complexity without the enforced discipline of object inheritance.
Consider the special case of a software project. If we allow data to mutate as it moves through our system it will bind elements irrevocably together because the data gains context from many of the element that employ it, and some elements will need that extra context to offer their own. There is a balance between building more but simpler tasks and fewer but more-complex tasks – that balance is a structural balance, not a scheduling one. If we allow tasks to be related more by scheduling constraints than by good structural design principles then our design is haphazard at best, arbitrary and unrealistic at worst. If we allow intimately related tasks to be widely separated by a multiplicity of interfaces then we are forced to bind them together with overly complex structures. Our project becomes rigid and inflexible. Senescence is an integral part of its design, for it cannot change, cannot evolve.
But we are not necessarily victims of complexity – we can still structure the abstract design process to manage and control complexity. We do this by managing the relationships between entities.
Relationships
To change model space once more, consider the exercise of building a house. Our starting point is an architect's plan.

House
- Architect's Plan
From this plan follows a project design, a procedure for translating the conceptual diagram into a real house.
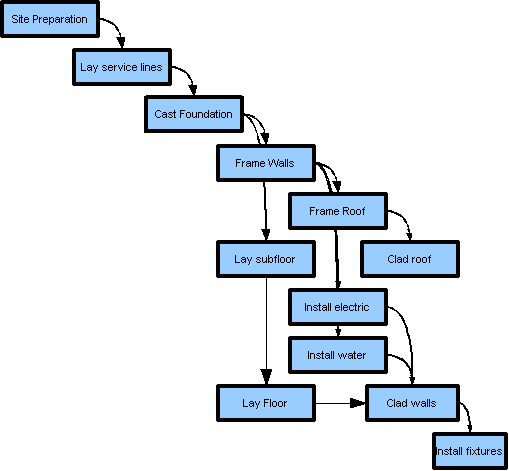
House
- 'Waterfall' schedule
Our project design is usually sequence-oriented (what tasks follow-on each other?). Sequence based project design is a powerful paradigm - so much so that it is easy to conflate scheduling with project engineering itself. In following this conventional approach we are assuming we know enough about what we are doing to anticipate any problems that might arise. For example, we are certainly wise enough to build the walls before we attempt the roof, but more subtle things might trip us up—and almost inevitably do. Essentially our capacity to design a project resolves to our ability to schedule its component parts, and our ablility to schedule to our ability to imagine the various steps of a project completely enough to anticipate their mutual influence.
- An architecture school designed lecture theaters and then belatedly built an external staircase after it became apparent that the only access to them was through a restroom.
- The designers of the Hindenburg wrapped a huge volume of hydrogen in spontaneously combustible fabric.
If instead of regarding project design purely as a scheduling exercise we regard it as an exercise in constructing relationships between entities then we start to see it in a completely different light —one far closer to the reality we are trying to craft.
Consider for example the following project sub-structure, which shows a fragment of the relationships between the various systems in our house - in this case the water systems. It is a directed structure, but not a sequential one. It is a kernel structure – the entities that serve and employ each other in dynamic interplay - the project's 'bones' if you will.
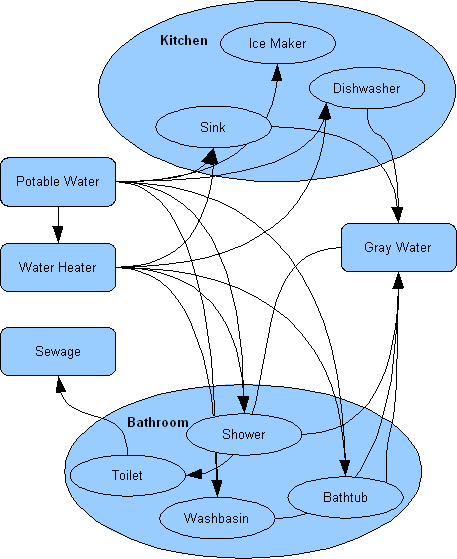
House - Component-based Elements
These relationships can be analysed numerically to yield the critical components of the project:
-
components that have little scope to influence their own evolution
-
components that deviate significantly from their peers in some respect
-
components that complexify the design without concomitantly simplifying it in some respect.
Happily there is a fair degree of synergy between orthodox schedule-based project design and relationship based design, and it is possible to extract critical components from schedule-based designs using algorithmic tools.

A
three-dimensional representation of resource-based task relationships.
The towers at the front (on the diagonal) represent tasks - the higher the tower, the more
complex the task. The pinnacles are a measure of how eccentric a task
is (how much it differs from its peers). Off-diagonal elements represent the contribution of other tasks to
the diagonal task's complexity.